Shannon McCarty, Lam Pham, Alora Thresher, Alexandria Wasgatt, Emma Whamond
This study investigates the transcription accuracy by AI speech recognition systems using natural language processing when interpreting standard American English dialects (SAE) versus African American Vernacular English (AAVE). We inspect the percentage of misidentified words, and the degree to which the speech is misidentified, by AI speech recognition systems through analyzing authentic speech found in YouTube videos. The accuracy of voice recognition with respect to AAVE will be determined by selecting for distinct AAVE features, such as G-dropping, the [θ] sound, reduction of consonant clusters, and non-standard usages of be. The methodology includes feeding YouTube clips of both SAE and AAVE through an AI speech recognition software, as well as examining YouTube’s auto-generated transcripts, which are created by automatic speech recognition based on the audio of the YouTube video. The purpose of this study is to bring attention to the needs of diversity in technology with regard to language variation, so that AI speech systems such as Amazon’s Alexa or Apple’s Siri are more accessible to all members of society, as well as to help destigmatize a variety of American English that has carried social, cultural, and historical stigma for centuries.
Introduction and Background
2020—American society finds itself at the thrilling forefront of technological innovation, yet is still plagued by racial inequality and systematic racism. Our study aimed to tackle a portion of this American duality from a sociolinguistic standpoint. We investigated AI speech recognition systems and the identification differences while processing speech of the standard American English dialect (SAE) versus African American Vernacular English (AAVE). SAE is most broadly defined as the most uniform, accepted, and understood language in the US. On the other hand, AAVE is not solely slang or a lesser form of SAE; rather, it is a language variety that has systematic linguistic patterns and carries social, cultural, and historical stigmas. We believe AI speech recognition systems will reflect our country’s racial biases by misinterpreting AAVE far more often than SAE. As these technologies become more commonplace and embedded in society, our study’s goal is to shed light on whether AI speech technology is inclusive of the AAVE dialect and its speakers.
Methods
An overview of AAVE linguistic features can be found in a paper discussing the matter by Erik Thomas (2007), though we narrowed our focus on the most defining features of AAVE in this study. These included G-dropping, the th sound (as in bath) becoming the f sound (as in fast), reduction of consonant clusters at the ends of words (wes side versus west side), and the use of the verb be (Singler, 1998).
The analysis of the main facets of the verb be included the dropping of be, the habitual be (Collins, 2006), the use of BIN and be done. The heavy focus on be was due to the fact that it is one of the biggest syntactic differences between SAE and AAVE (Lanehart, 2015). As a result, the variants of be were most likely to affect the transcription performance of voice recognition software when processing AAVE.
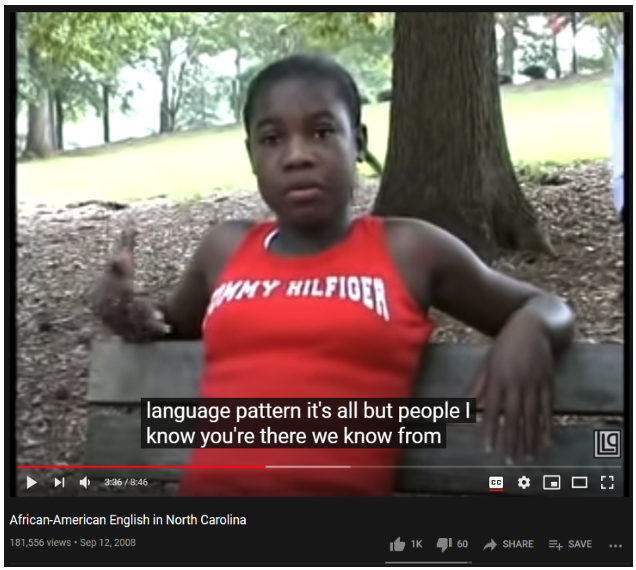
This study used the abundant linguistic resources available from YouTube to exhibit the use of SAE and AAVE dialects. We compiled audio clips of authentic, normal speech in both of these varieties and fed the audio clips into an AI transcription software, specifically dictation.io/speech, as well as examined YouTube’s AI-generated closed captions. It was important to ensure that the captions we used on YouTube were the auto-generated ones, and not captions that had been manually entered by the uploader.
To determine what percentage of speech and what types of features of the dialects were misidentified by the AI speech recognition systems, we quantified the data by categorizing the accuracy of the AI transcriptions into four groups: “All,” meaning All of the words were picked up, “Most,” “Few,” or “None.” If every single word in the audio recording was transcribed correctly by the AI speech recognition system, then that audio clip was placed in the “All words picked up” group. If most words or only a few words were transcribed correctly by the AI speech recognition system, then that audio clip was placed in “Most” and “Few” groups, respectively. And if nothing in the audio clip was transcribed correctly by the AI speech recognition system, then that audio clip was placed in the “None” group.
Our hypothesis was that the percentage of interpretation inaccuracy in AI speech recognition systems while interpreting AAVE would be significantly higher than the inaccuracy recorded by speech recognition software while interpreting SAE (i.e. more AAVE audio clips would land in the “Few” and “None” transcription accuracy groups). This would lead to an expectation that voice recognition software is globally less effective for speakers of AAVE.
Results/Analysis
The results of this study were overall in line with the hypothesis—the transcription software picked up more SAE words than AAVE words. The vast majority of AAVE video samples collected had “Few” words transcribed correctly. Figure 1 shows the amount of AAVE words picked up by the transcription software. Our study found that for all of the clips of AAVE:
-
- 16.7% “All” words were picked up
- 16.7% “Most” words were picked up
- 56.7% “Few” words were picked up
- 10.0% “None” of the words were picked up
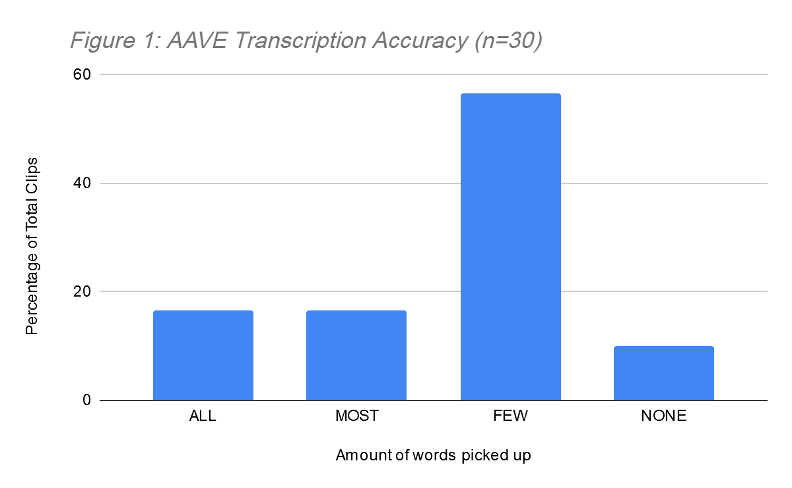
It is noteworthy that the transcription software was unable to pick up the majority of AAVE speech when the video clips were similar to the SAE video clips with regard to background noise, speaker volume, etc. We believe this is largely due to AAVE phonetics rather than AAVE syntax and word choice, which is what we were focusing on in this study.
On the other hand, all video samples of SAE fell under “All” or “Most” transcription accuracy. The SAE video clips had the majority of their words picked up and transcribed correctly. According to Figure 2:
-
- 31.6% of the clips had all their words picked up
- 68.4% had the majority of their words picked up

The results of transcribing SAE versus the results of AAVE are drastically different; we believe this is largely due to the phonetic differences between the two English varieties. The only time SAE was not picked up was when the speaker was speaking faster than normal. All of the words could have blended together, and as a result, the transcription software was not able to distinguish what was being said.
Another unexpected observation for both AAVE and SAE was that women speakers were not picked up as often as male speakers; AAVE female speakers made up 66.7% of the “None” category, despite comprising less than 20% of our AAVE samples.
Limitations
We had some limitations in our project as well. Due to COVID and time restrictions, our sample size was regrettably small at only 49 clips. We also had a few clips become unusable between the time of our finding them and analyzing them. As a result of the small sample size, we ended up noticing a huge, unexpected difference between the transcription accuracy of male versus female speakers of AAVE, but we weren’t able to draw any solid conclusions as to whether this difference is representative of a larger population. However, the difference was quite apparent within the random pool we gathered, so a study with equal amounts of male and female AAVE speakers could address this issue more equitably.
Speakers that were present in the room would also have enabled a more accurate representation of AAVE and voice recognition software’s real-world interaction. Our computers and phones were limited due to the differing microphone quality, which could have influenced the amount of words the voice recognition software picked up. In addition, we had planned to use our phones’ dictation softwares as the primary method of data acquisition, which ended up being wholly impossible, so we only had the time to find and use one transcription site.
Many of the video clips were filmed in neighborhoods, with background noise included, such as cars going by, wind, and people talking. This could also have limited our transcription site and created another layer of ambiguity. However, SAE clips with similar amounts of background noise that were played were transcribed (mostly) correctly. So it is unclear if the background noise is fully a limitation or an example of voice recognition software not picking up AAVE.
Lastly, we began to wonder if the phonetics of AAVE had more of an effect on our voice recognition software than the syntax did—that is, we wondered whether the sound of AAVE was more impactful than the sentence structure. A few of us used the software to speak sentences that were syntactically AAVE, but not phonetically, as none of the researchers of this study were AAVE speakers. Those sentences were transcribed correctly, including AAVE syntax. However, we did not have enough time to pursue that avenue of research, but it would be a promising starting point for any future projects.
Discussion and Conclusions
This investigation was intended solely to pursue the question of whether there is a racially-based difference in accuracy of voice recognition software. Despite the unexpectedly small scope of our study, we believe our results are sufficient to prompt further investigation into the reasons as to why there is such a stark difference in accuracy.
To that end, a question that arises naturally is whether closing the gap in accuracy is as simple as writing and including a few more lines of code. If it is, then what’s preventing this from happening now? And if the voice recognition software instead needs to be re-constructed from the ground up, then that, in turn, spawns a whole host of follow-up questions (e.g. Who’s paying for this development? Who’s working on it? How long will it take?).
It is, as with any discussion of racially-based imbalances, also worth considering systemic variables at play. Another question worth pursuing is whether there is a higher average level of inaccessibility to the technology sector for speakers of AAVE compared to speakers of SAE, which would contribute to a broad range of consequences—one of which might be the discrepancy in accuracy of voice transcription softwares demonstrated in this study.
In 2016, Rickford and King cited Schneider (1996) to describe AAVE as “the US English dialect most examined by linguists for quite some time.” In the academic world, it’s common knowledge that the prejudices held against AAVE — and its speakers — have no basis in fact. The drastic difference in voice recognition software transcription accuracy between SAE and AAVE is not only one more imbalance to correct in pursuit of a fully equitable society, but also a symptom of the systemic racism that influences all aspects of daily life. Studies like this one which stop at identifying the problem are only the first step; the next is to examine why the problem exists in the first place, so that work to resolve the inequity can begin.
References
Collins, C. (2006). A fresh look at habitual be in AAVE. CREOLE LANGUAGE LIBRARY, 29, 203.
Koenecke, A., Nam, A., Lake, E., Nudell, J., Quartey, M., Mengesha, Z., Toups, C., Rickford, J., Jurafsky, D., & Goel, S. (2020). Racial disparities in automated speech recognition. Proceedings of the National Academy of Sciences, 117(14), 7684-7689.
Lanehart, S. (Ed.). (2015). The Oxford Handbook of African American Language. Oxford University Press.
Lippi, R., Donati, S., Lippi-Green, R., & Donati, R. (1997). English with an accent: Language, ideology, and discrimination in the United States. Psychology Press.
Rickford, J. R., & King, S. (2016). Language and linguistics on trial: Hearing Rachel Jeantel (and other vernacular speakers) in the courtroom and beyond. Language, 92(4), 948-988.
Singler, John Victor. “What’s not new in AAVE.” American Speech 73.3 (1998): 227-256.
Thomas, E. R. (2007). Phonological and phonetic characteristics of African American vernacular English. Language and Linguistics Compass, 1(5), 450-475.